阿尔法围棋(AlphaGo)是第一个击败人类职业围棋选手、第一个战胜围棋世界冠军的人工智能程序,由谷歌(Google)旗下DeepMind公司戴密斯·哈萨比斯领衔的团队开发。

那么阿尔法狗的工作原理是什么?相关技术又有哪些呢?下面让我们一起来看看。
工作原理
阿尔法围棋(AlphaGo)为了应对围棋的复杂性,结合了监督学习和强化学习的优势。它通过训练形成一个策略网络(policynetwork),将棋盘上的局势作为输入信息,并对所有可行的落子位置生成一个概率分布。然后,训练出一个价值网络(valuenetwork)对自我对弈进行预测,以-1(对手的绝对胜利)到1(AlphaGo的绝对胜利)的标准,预测所有可行落子位置的结果。这两个网络自身都十分强大,而阿尔法围棋将这两种网络整合进基于概率的蒙特卡罗树搜索(MCTS)中,实现了它真正的优势。新版的阿尔法围棋产生大量自我对弈棋局,为下一代版本提供了训练数据,此过程循环往复。
在获取棋局信息后,阿尔法围棋会根据策略网络(policynetwork)探索哪个位置同时具备高潜在价值和高可能性,进而决定最佳落子位置。在分配的搜索时间结束时,模拟过程中被系统最频繁考察的位置将成为阿尔法围棋的最终选择。在经过先期的全盘探索和过程中对最佳落子的不断揣摩后,阿尔法围棋的搜索算法就能在其计算能力之上加入近似人类的直觉判断

围棋棋盘是19x19路,所以一共是361个交叉点,每个交叉点有三种状态,可以用1表示黑子,-1表示白字,0表示无子,考虑到每个位置还可能有落子的时间、这个位置的气等其他信息,我们可以用一个361*n维的向量来表示一个棋盘的状态。我们把一个棋盘状态向量记为s。
当状态s下,我们暂时不考虑无法落子的地方,可供下一步落子的空间也是361个。我们把下一步的落子的行动也用361维的向量来表示,记为a。
这样,设计一个围棋人工智能的程序,就转换成为了,任意给定一个s状态,寻找最好的应对策略a,让你的程序按照这个策略走,最后获得棋盘上最大的地盘。
三大核心技术
AlphaGo结合了3大块技术:先进的搜索算法、机器学习算法(即强化学习),以及深度神经网络。这三者的关系大致可以理解为:
1、蒙特卡洛树搜索(MCTS)是大框架
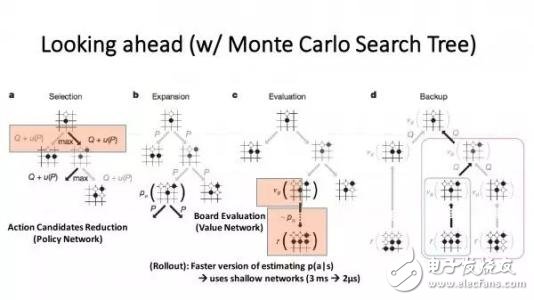
实质上可以看成一种增强学习
蒙特卡罗树搜索(MCTS)会逐渐的建立一颗不对称的树。可以分为四步并反复迭代:
(1)选择
从根节点,也就是要做决策的局面R出发向下选择一个最急迫需要被拓展的节点T;局面R是第一个被检查的节点,被检查的节点如果存在一个没有被评价过的招式m,那么被检查的节点在执行m后得到的新局面就是我们所需要展开的T;如果被检查的局面所有可行的招式已经都被评价过了,那么利用ucb公式得到一个拥有最大ucb值的可行招式,并且对这个招式产生的新局面再次进行检查;如果被检查的局面是一个游戏已经结束的游戏局面,那么直接执行步骤4;通过反复的进行检查,最终得到一个在树的最底层的最后一次被检查的局面c和它的一个没有被评价过的招式m,执行步骤2。
(2)拓展
对于此时存在于内存中的局面c,添加一个它的子节点。这个子节点由局面c执行招式m而得到,也就是T。
(3)模拟
从局面T出发,双方开始随机的落子。最终得到一个结果(win/lost),以此更新T节点的胜利率。
(4)反向传播
在T模拟结束之后,它的父节点c以及其所有的祖先节点依次更新胜利率。一个节点的胜利率为这个节点所有的子节点的平均胜利率。并从T开始,一直反向传播到根节点R,因此路径上所有的节点的胜利率都会被更新。
之后,重新从第一步开始,不断地进行迭代。使得添加的局面越来越多,则对于R所有的子节点的胜利率也越来越准。最后,选择胜利率最高的招式。
实际应用中,mcts还可以伴随非常多的改进。我描述的这个算法是mcts这个算法族中最出名的uct算法,现在大部分著名的ai都在这个基础上有了大量的改进了。 2、强化学习(RL)是学习方法,用来提升AI的实力。
2、强化学习 (RL) 是学习方法,用来提升AI的实力
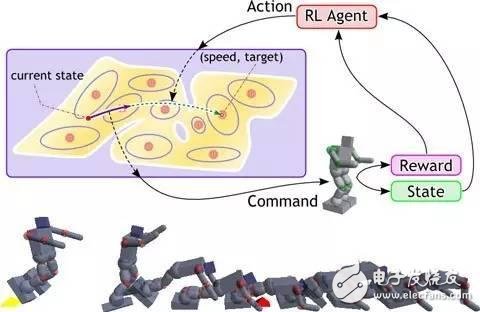
强化学习是从动物学习、参数扰动自适应控制等理论发展而来,其基本原理是:
如果Agent的某个行为策略导致环境正的奖赏(强化信号),那么Agent以后产生这个行为策略的趋势便会加强。Agent的目标是在每个离散状态发现最优策略以使期望的折扣奖赏和最大。
强化学习把学习看作试探评价过程,Agent选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈给Agent,Agent根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化(奖)的概率增大。选择的动作不仅影响立即强化值,而且影响环境下一时刻的状态及最终的强化值。
强化学习不同于连接主义学习中的监督学习,主要表现在教师信号上,强化学习中由环境提供的强化信号是Agent对所产生动作的好坏作一种评价(通常为标量信号),而不是告诉Agent如何去产生正确的动作。由于外部环境提供了很少的信息,Agent必须靠自身的经历进行学习。通过这种方式,Agent在行动一一评价的环境中获得知识,改进行动方案以适应环境。
强化学习系统学习的目标是动态地调整参数,以达到强化信号最大。若已知r/A梯度信息,则可直接可以使用监督学习算法。因为强化信号r与Agent产生的动作A没有明确的函数形式描述,所以梯度信息r/A无法得到。因此,在强化学习系统中,需要某种随机单元,使用这种随机单元,Agent在可能动作空间中进行搜索并发现正确的动作。
3、深度神经网络(DNN)是工具,用来拟合局面评估函数和策略函数

深度神经网络,也被称为深度学习,是人工智能领域的重要分支,根据麦卡锡(人工智能之父)的定义,人工智能是创造像人一样的智能机械的科学工程。
通过比较当前网络的预测值和我们真正想要的目标值,再根据两者的差异情况来更新每一层的权重矩阵(比如,如果网络的预测值高了,就调整权重让它预测低一些,不断调整,直到能够预测出目标值)。因此就需要先定义“如何比较预测值和目标值的差异”,这便是损失函数或目标函数(lossfuncTIonorobjecTIvefuncTIon),用于衡量预测值和目标值的差异的方程。lossfuncTIon的输出值(loss)越高表示差异性越大。那神经网络的训练就变成了尽可能的缩小loss的过程。
所用的方法是梯度下降(Gradientdescent):通过使loss值向当前点对应梯度的反方向不断移动,来降低loss。一次移动多少是由学习速率(learningrate)来控制的。
总结
这三大技术都不是AlphaGo或者DeepMind团队首创的技术。但是强大的团队将这些结合在一起,配合Google公司强大的计算资源,成就了历史性的飞跃。
